使用 recipes 进行特征工程
特征工程(Feature Engineering) 是指将原始数据转化为模型可以利用的特征的过程。通过这个过程,我们能够更好地表示潜在问题,从而提高模型的性能。
特征(Feature) 可以理解为模型预测所需要的某种表示或者属性。譬如在房价预测问题中,房屋的面积、房间数量、地段等都可以被视为特征。
以下是一些常见的特征表示:
交互项(Interactions) :这是通过组合原有的特征创建新的特征。例如,如果我们有两个特征 A 和 B,我们可以创建一个新的特征 A*B 来表示 A 和 B 的交互效应。
多项式扩展/样条函数(Polynomial expansions/splines) :这是通过对原有特征进行非线性转换创建新的特征。例如,如果我们有一个特征 X,我们可以创建新的特征 X^2, X^3 等来捕捉 X 的非线性效应。
主成分分析(PCA)特征提取 :这是一种降维技术,通过将原有的多个特征转化为少数几个主成分(也就是新的特征),从而保留数据中的主要信息。这种方法通常用于处理具有多重共线性的高维数据。
以上就是特征工程的基本概念以及一些常见的特征表示方式。通过合适的特征工程,我们能够提取出更有价值的信息,从而帮助模型更好地理解和预测问题。
特征工程的软件包
recipes 包是 R 语言中的一个用于数据预处理和特征工程的工具包。它提供了一种灵活且强大的方式来创建和管理模型需要的预处理步骤。这些步骤可以包括数据清洗、数据转换、特征选择、特征构建等。
以下是 recipes 包的一些主要功能:
数据预处理 :recipes 包提供了许多函数来进行数据预处理,如缩放和中心化(标准化)、处理缺失值、离群值检测和处理等。
特征选择 :recipes 包可以帮助我们选择最重要的特征,以降低模型的复杂性和过拟合的风险。
特征工程 :recipes 包可以用于创建新的特征,如基于现有特征的数学变换(例如平方、对数变换等)、交互项、虚拟变量(独热编码)等。
简易操作 :所有的预处理步骤都可以被封装在一个 “recipe” 对象中,这使得整个预处理过程更加组织化和可复现。
总的来说,recipes 包是一个非常有用的工具,它可以帮助我们更有效地进行数据预处理和特征工程,并应用到模型开发的工作流程中。
对时间变量进行特征提取
对时间变量进行特征提取有很多常见的方法,以下是一些例子:
时间分解 :将时间戳分解为年、月、日、小时、分钟和秒。这可以帮助我们理解时间的不同组成部分如何影响目标变量。
季节性特征 :你可以创建表示季节性信息的特征,如季度、月份、一周中的哪一天、一天中的哪个时段等。
节假日和事件 :如果数据中包含特定的节假日或事件,这可能会影响到目标变量。此时,可以创建一个二元特征来表示这些特殊的日期或事件。
时间间隔 :计算两个日期之间的时间差,例如用户上次购买产品到现在的天数。
趋势 :如果你的数据集跨越了很长一段时间,那么可能存在一些长期趋势。在这种情况下,你可以创建一个特征来捕捉这种趋势,例如数据点距离开始日期的天数。
滑动窗口统计 :例如过去7天或30天的平均值、最小值、最大值等。
这些只是一部分常见的处理时间变量的策略,具体采用哪种策略需要结合实际的业务场景和问题来决定。
对因子变量进行特征提取
对因子变量进行特征提取的方法有很多种,下面列出了一些常见的方法:
独热编码(One-Hot Encoding) :也被称为虚拟变量,这是最常见的编码方法。每个类别都被转换为一个二元变量(即0或1)。例如,如果有一个颜色的因子变量包含“红色”,“蓝色”和“绿色”三个级别,那么我们可以创建三个新的二元变量,分别表示这个观察是不是红色,是不是蓝色,是不是绿色。
标签编码(Label Encoding) :将每个类别映射到一个整数。这种方式适合于类别之间存在自然顺序的情况,比如评级(高、中、低)。
二进制编码(Binary Encoding) :首先,将所有类别按照一定的顺序编码为连续的整数;然后,将这些整数转换为二进制形式。这种方式特别适合高基数特征,因为它可以大大减少新生成的特征的数量。
哈希编码(Hashing Encoding) :哈希编码通过哈希函数,将类别映射到更小的固定长度的列。这种方式对于处理具有大量类别的变量非常有效。
目标编码(Target Encoding) :也被称为均值编码或者响应编码,这种方式是基于类别目标变量的平均值来对类别进行编码。它可以帮助模型捕捉到类别和目标变量之间可能存在的关系,但是如果不慎重处理,容易导致过拟合。
嵌入式方法(Embedding) :这是一种神经网络处理因子变量的方式,将每个类别映射到一个多维空间中的一个点,可以捕获更复杂的关系。
这些方法各有优缺点,选择哪一种取决于具体的问题和数据。例如,独热编码可能会产生很多列,而哈希编码可能会产生碰撞(不同的类别映射到同一哈希值)。
下面以房价预测模型为例,展示对数据中的因子变量进行特征提取的方法。
# recipes-startup library (tidymodels)
── Attaching packages ────────────────────────────────────── tidymodels 1.1.1 ──
✔ broom 1.0.5 ✔ recipes 1.0.9
✔ dials 1.2.0 ✔ rsample 1.2.0
✔ dplyr 1.1.4 ✔ tibble 3.2.1
✔ ggplot2 3.4.4 ✔ tidyr 1.3.0
✔ infer 1.0.5 ✔ tune 1.1.2
✔ modeldata 1.2.0 ✔ workflows 1.1.3
✔ parsnip 1.1.1 ✔ workflowsets 1.0.1
✔ purrr 1.0.2 ✔ yardstick 1.2.0
── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
✖ purrr::discard() masks scales::discard()
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ recipes::step() masks stats::step()
• Search for functions across packages at https://www.tidymodels.org/find/
library (modeldatatoo)# Add another package: library (textrecipes)# Max's usual settings: tidymodels_prefer ()theme_set (theme_bw ())options (pillar.advice = FALSE , pillar.min_title_chars = Inf
# data-import data (hotel_rates)set.seed (295 )<- %>% sample_n (5000 ) %>% arrange (arrival_date) %>% select (- arrival_date) %>% mutate (company = factor (as.character (company)),country = factor (as.character (country)),agent = factor (as.character (agent))set.seed (4028 )<- initial_split (hotel_rates, strata = avg_price_per_room)<- training (hotel_split)<- testing (hotel_split)<- vfold_cv (hotel_train, strata = avg_price_per_room)
# 10-fold cross-validation using stratification
# A tibble: 10 × 2
splits id
<list> <chr>
1 <split [3372/377]> Fold01
2 <split [3373/376]> Fold02
3 <split [3373/376]> Fold03
4 <split [3373/376]> Fold04
5 <split [3373/376]> Fold05
6 <split [3374/375]> Fold06
7 <split [3375/374]> Fold07
8 <split [3376/373]> Fold08
9 <split [3376/373]> Fold09
10 <split [3376/373]> Fold10
<- recipe (avg_price_per_room ~ ., data = hotel_train) %>% step_dummy (all_nominal_predictors ()) %>% step_zv (all_predictors ()) %>% step_normalize (all_numeric_predictors ()) %>% step_corr (all_numeric_predictors (), threshold = 0.9 )summary (hotel_rec)
# A tibble: 27 × 4
variable type role source
<chr> <list> <chr> <chr>
1 lead_time <chr [2]> predictor original
2 stays_in_weekend_nights <chr [2]> predictor original
3 stays_in_week_nights <chr [2]> predictor original
4 adults <chr [2]> predictor original
5 children <chr [2]> predictor original
6 babies <chr [2]> predictor original
7 meal <chr [3]> predictor original
8 country <chr [3]> predictor original
9 market_segment <chr [3]> predictor original
10 distribution_channel <chr [3]> predictor original
# ℹ 17 more rows
<- recipe (avg_price_per_room ~ ., data = hotel_train) %>% step_dummy (all_nominal_predictors ()) %>% step_zv (all_predictors ()) %>% step_normalize (all_numeric_predictors ()) %>% :: step_umap (all_numeric_predictors (), outcome = vars (avg_price_per_room))summary (hotel_rec)
# A tibble: 27 × 4
variable type role source
<chr> <list> <chr> <chr>
1 lead_time <chr [2]> predictor original
2 stays_in_weekend_nights <chr [2]> predictor original
3 stays_in_week_nights <chr [2]> predictor original
4 adults <chr [2]> predictor original
5 children <chr [2]> predictor original
6 babies <chr [2]> predictor original
7 meal <chr [3]> predictor original
8 country <chr [3]> predictor original
9 market_segment <chr [3]> predictor original
10 distribution_channel <chr [3]> predictor original
# ℹ 17 more rows
<- recipe (avg_price_per_room ~ ., data = hotel_train) %>% step_dummy (all_nominal_predictors ()) %>% step_zv (all_predictors ()) %>% step_normalize (all_numeric_predictors ()) %>% :: step_umap (all_numeric_predictors (), outcome = vars (avg_price_per_room))summary (hotel_rec)
# A tibble: 27 × 4
variable type role source
<chr> <list> <chr> <chr>
1 lead_time <chr [2]> predictor original
2 stays_in_weekend_nights <chr [2]> predictor original
3 stays_in_week_nights <chr [2]> predictor original
4 adults <chr [2]> predictor original
5 children <chr [2]> predictor original
6 babies <chr [2]> predictor original
7 meal <chr [3]> predictor original
8 country <chr [3]> predictor original
9 market_segment <chr [3]> predictor original
10 distribution_channel <chr [3]> predictor original
# ℹ 17 more rows
<- recipe (avg_price_per_room ~ ., data = hotel_train) %>% step_dummy (all_nominal_predictors ()) %>% step_zv (all_predictors ()) %>% step_normalize (all_numeric_predictors ()) %>% step_spline_natural (arrival_date_num, deg_free = 10 )summary (hotel_rec)
# A tibble: 27 × 4
variable type role source
<chr> <list> <chr> <chr>
1 lead_time <chr [2]> predictor original
2 stays_in_weekend_nights <chr [2]> predictor original
3 stays_in_week_nights <chr [2]> predictor original
4 adults <chr [2]> predictor original
5 children <chr [2]> predictor original
6 babies <chr [2]> predictor original
7 meal <chr [3]> predictor original
8 country <chr [3]> predictor original
9 market_segment <chr [3]> predictor original
10 distribution_channel <chr [3]> predictor original
# ℹ 17 more rows
这段代码主要实现了对数据集 hotel_rates 进行预处理和特征工程的操作。具体来说:
设置环境 :加载需要的库并进行一些通用设置。
数据导入和初步处理 :首先从 hotel_rates 数据中随机抽取了5000个样本,然后去除了 arrival_date 列,最后将 company、country 和 agent 三列转换为因子类型。
创建交叉验证分割 :使用 vfold_cv 函数对训练集进行10折交叉验证分割,并按照 avg_price_per_room 这一列进行分层抽样。
创建数据预处理步骤(recipe) :使用 recipe 函数创建一个数据预处理食谱。在这个过程中,执行了以下步骤:
使用 step_dummy 将所有名义预测变量 转换为虚拟(dummy)变量。
使用 step_zv 删除所有零方差预测变量。
使用 step_normalize 对所有数值预测变量进行标准化(即变换为均值为0、标准差为1的正态分布)。
在第一个食谱中,使用 step_corr 删除所有与其他数值预测变量相关性大于0.9的预测变量。
在第二、三个食谱中,使用 step_umap 对所有数值预测变量进行UMAP降维,并将 avg_price_per_room 作为目标变量。
在第四个食谱中,使用 step_spline_natural 对 arrival_date_num 这一预测变量进行自然样条变换。
每次创建完一个食谱后,都使用了 summary 函数查看了该食谱的内容。这样可以帮助我们理解每一步预处理操作对数据的影响。
下面这段代码首先创建了一个名为 hotel_indicators 的预处理 “recipe”,然后利用这个 “recipe” 和简单线性回归模型建立了一个工作流(workflow),最后使用10折交叉验证的方式对这个工作流进行了拟合并评估模型性能。
具体步骤包括:
<- recipe (avg_price_per_room ~ ., data = hotel_train) %>% step_YeoJohnson (lead_time) %>% step_dummy (all_nominal_predictors ()) %>% step_zv (all_predictors ()) %>% step_spline_natural (arrival_date_num, deg_free = 10 )summary (hotel_indicators)
# A tibble: 27 × 4
variable type role source
<chr> <list> <chr> <chr>
1 lead_time <chr [2]> predictor original
2 stays_in_weekend_nights <chr [2]> predictor original
3 stays_in_week_nights <chr [2]> predictor original
4 adults <chr [2]> predictor original
5 children <chr [2]> predictor original
6 babies <chr [2]> predictor original
7 meal <chr [3]> predictor original
8 country <chr [3]> predictor original
9 market_segment <chr [3]> predictor original
10 distribution_channel <chr [3]> predictor original
# ℹ 17 more rows
这段代码是创建一个预处理数据的 “recipe”。主要步骤如下:
recipe(avg_price_per_room ~ ., data = hotel_train):建立一个recipe对象,其目标(响应变量)是avg_price_per_room,预测变量是hotel_train数据集中的所有其他变量。
step_YeoJohnson(lead_time):对lead_time列应用 Yeo-Johnson 变换。Yeo-Johnson 变换是一种用于正态化数据和管理异方差性的方法,可以用于正数、负数和零的数据。
step_dummy(all_nominal_predictors()):将所有名义型预测变量转换为虚拟(dummy)变量,也就是进行独热编码。这样做能够让我们把包含多类别的名义变量转换为二元变量,使得模型能够处理。
step_zv(all_predictors()):删除所有零方差预测变量。零方差预测变量是指在所有观察中值都相同的变量,这样的变量对模型预测通常没有帮助。
step_spline_natural(arrival_date_num, deg_free = 10):对arrival_date_num这一变量进行自然样条变换,自由度设置为10。样条变换能够帮助处理非线性关系,尤其是当我们预期某个预测变量和响应变量之间存在复杂的非线性关系时。
这个recipe定义了数据预处理和特征工程的步骤,后续可以通过 prep() 和 bake() 函数来实施这个recipe。
<- metric_set (mae, rsq)
定义评估指标:通过 metric_set(mae, rsq) 命令定义了两个模型评估指标,即平均绝对误差(mean absolute error,mae)和决定系数(R-squared,rsq)。
\begin{align}
MAE &= \frac{1}{n}\sum_{i=1}^n |y_i - \hat{y}_i| \notag \\
R^2 &= cor(y_i, \hat{y}_i)^2
\end{align}
\tag{2.1}
set.seed (9 )<- workflow () %>% add_recipe (hotel_indicators) %>% add_model (linear_reg ())
创建工作流:建立了一个包含预处理 “recipe” 和简单线性回归模型的工作流。
<- control_resamples (save_pred = TRUE )<- %>% fit_resamples (hotel_rs, control = ctrl, metrics = reg_metrics)
→ A | warning: prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
There were issues with some computations A: x1
There were issues with some computations A: x2
There were issues with some computations A: x9
There were issues with some computations A: x9
拟合并评估模型:通过 fit_resamples 函数将工作流应用到10折交叉验证的每一个分割中,并计算了在每一个分割中模型的评估指标。结果保存在 hotel_lm_res 中。
collect_metrics (hotel_lm_res)
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 mae standard 16.7 10 0.251 Preprocessor1_Model1
2 rsq standard 0.883 10 0.00532 Preprocessor1_Model1
收集评估指标:使用 collect_metrics(hotel_lm_res) 命令收集模型的评估指标。
# Since we used `save_pred = TRUE` <- collect_predictions (hotel_lm_res)%>% print (n = 7 )
# A tibble: 3,749 × 5
id .pred .row avg_price_per_room .config
<chr> <dbl> <int> <dbl> <chr>
1 Fold01 26.2 31 54 Preprocessor1_Model1
2 Fold01 23.0 35 48 Preprocessor1_Model1
3 Fold01 68.9 45 50 Preprocessor1_Model1
4 Fold01 60.2 47 55 Preprocessor1_Model1
5 Fold01 48.6 59 52.8 Preprocessor1_Model1
6 Fold01 49.0 67 49 Preprocessor1_Model1
7 Fold01 49.0 72 49 Preprocessor1_Model1
# ℹ 3,742 more rows
收集预测结果:因为在 control_resamples 函数中设置了 save_pred = TRUE,所以我们可以通过 collect_predictions(hotel_lm_res) 命令收集模型在10折交叉验证的每一个分割中的预测结果。
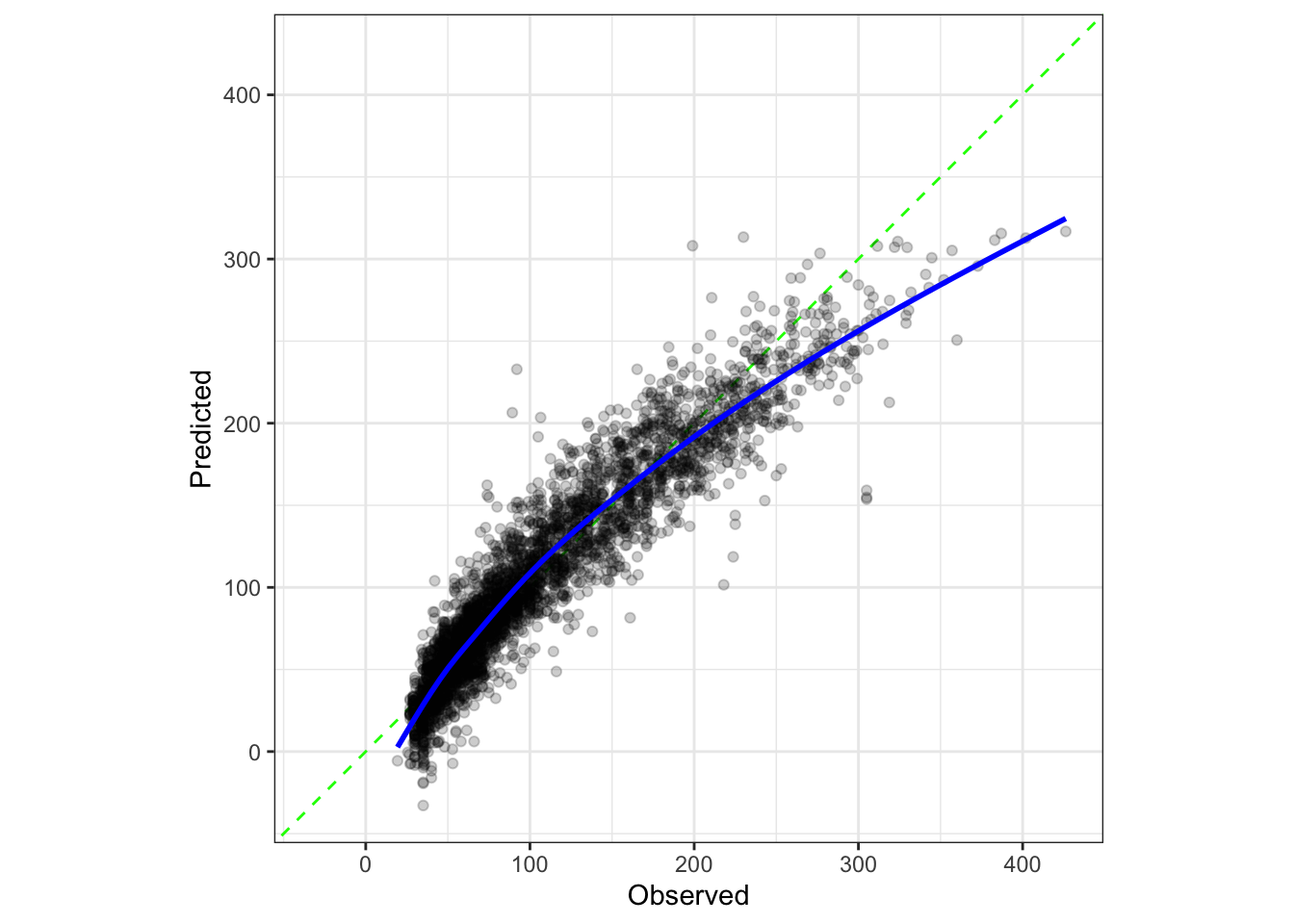
## Calibration Plot #| label: fig-lm-cal-plot #| fig-width: 5 #| fig-height: 5 library (probably)cal_plot_regression (hotel_lm_res, alpha = 1 / 5 )
绘制校准图:使用 cal_plot_regression 函数绘制了模型的校准图,这是一种用于评估回归模型预测精度的可视化方法。
对 agent 进行特征工程
使用分类汇总
下面这段代码包括两部分:首先对agent字段进行统计并绘制直方图,然后构建一个新的预处理”recipe”,使用了一个新的步骤:step_other()。
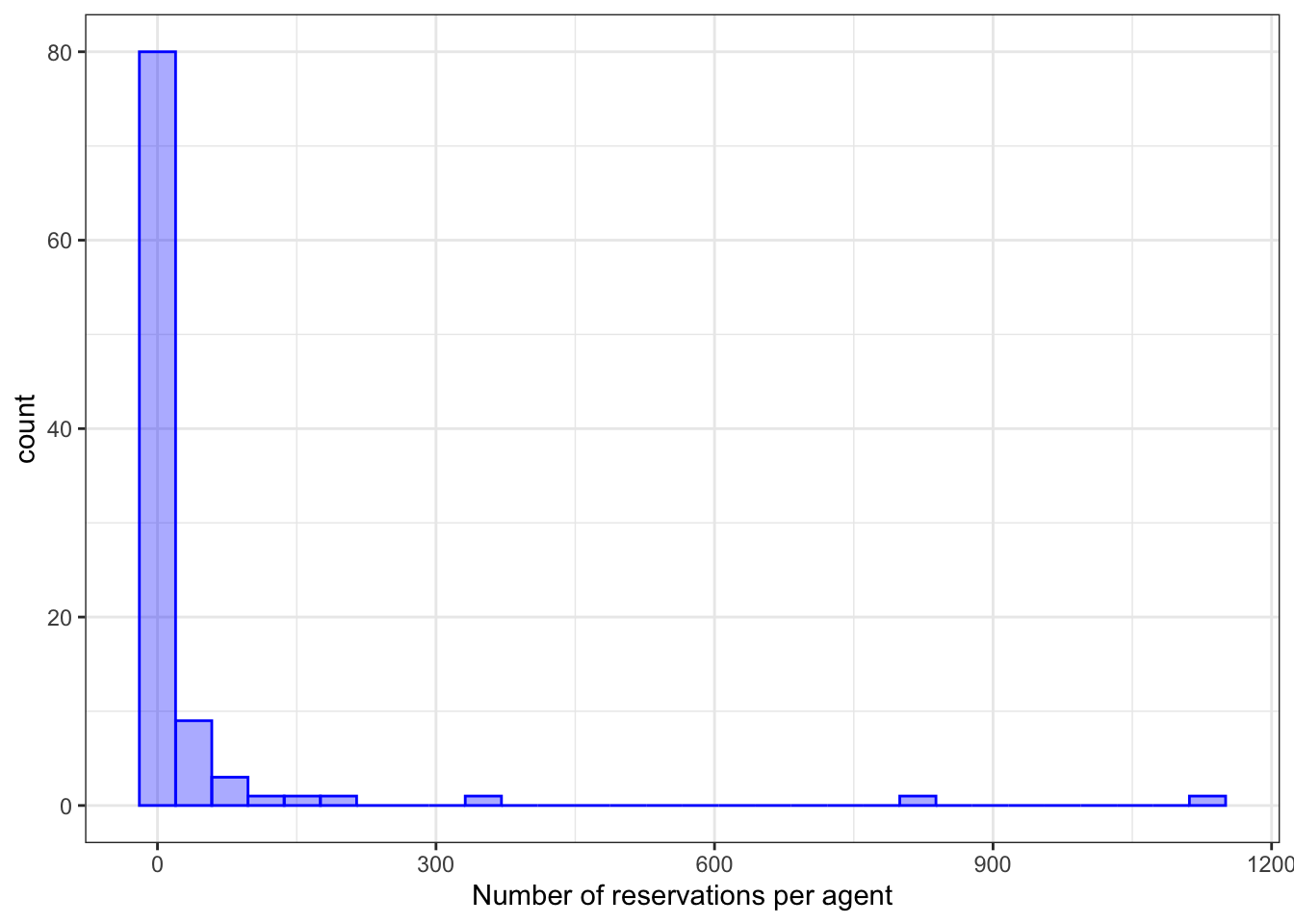
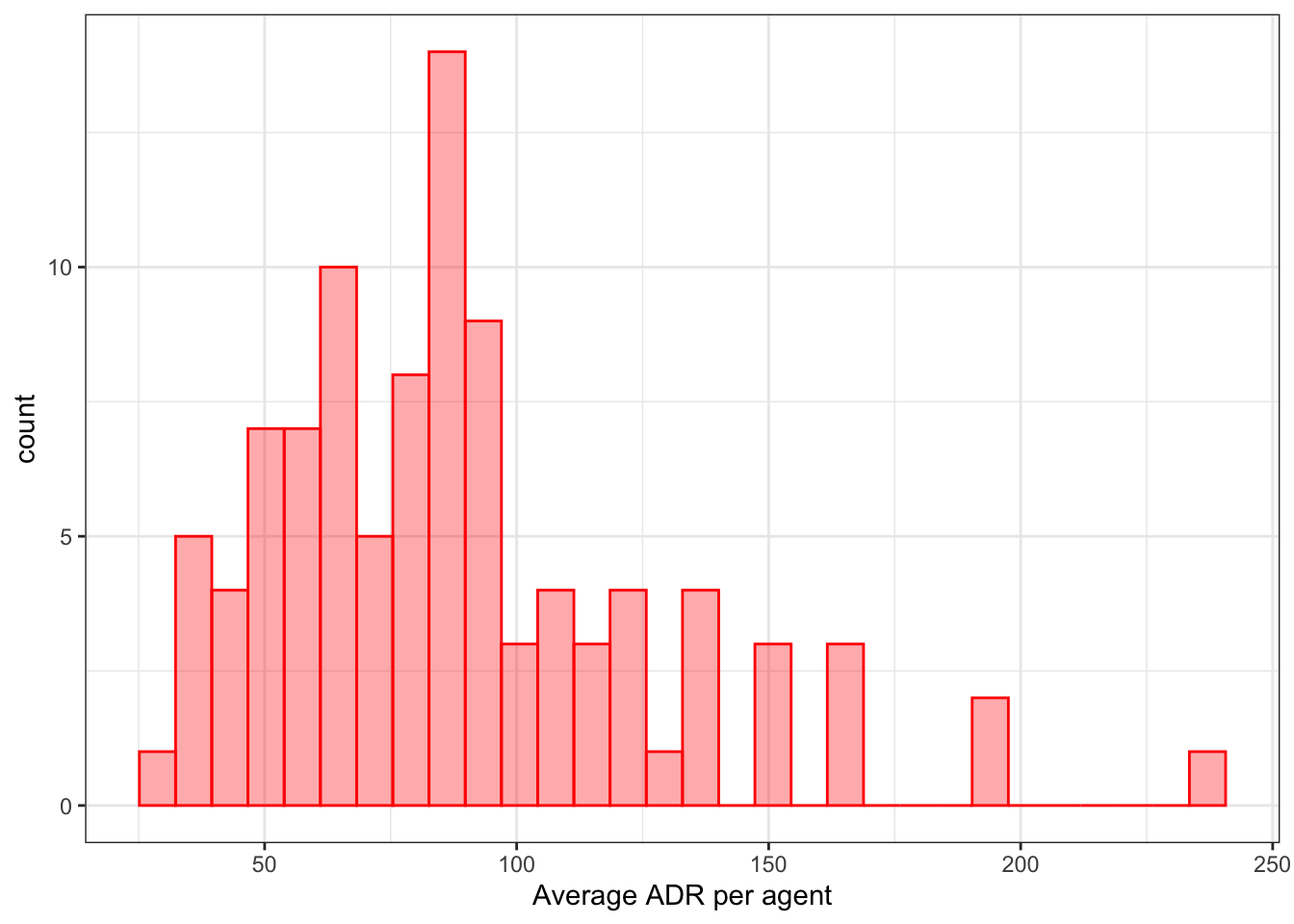
通过分析发现有一些 agent 出现的频率很低,这种情况下可以将其合并到 other 组中。
<- %>% group_by (agent) %>% summarize (ADR = mean (avg_price_per_room), num_reservations = n (),.groups = "drop" %>% mutate (agent = reorder (agent, ADR))%>% ggplot (aes (x = num_reservations)) + geom_histogram (bins = 30 , col = "blue" , fill = "blue" , alpha = 1 / 3 ) + labs (x = "Number of reservations per agent" )%>% ggplot (aes (x = ADR)) + geom_histogram (bins = 30 , col = "red" , fill = "red" , alpha = 1 / 3 ) + labs (x = "Average ADR per agent" )
代理统计 :对 hotel_train 数据集按 agent 进行分组,并计算每个代理的平均房价(ADR)和预订数量(num_reservations)。然后, 这些统计信息被用来创建两个直方图,分别显示了每个代理的预订数量和平均ADR。
<- recipe (avg_price_per_room ~ ., data = hotel_train) %>% step_mutate (original = agent) %>% step_other (agent, threshold = 0.001 ) %>% step_dummy (all_nominal_predictors ()) %>% step_zv (all_predictors ()) %>% step_spline_natural (arrival_date_num, deg_free = 10 ) %>% prep () %>% tidy (number = 2 )<- length (unique (hotel_train$ agent)))<- num_agents - length (retained_agents$ retained))
新的预处理”recipe” :新的recipe和之前的非常相似,但增加了一个 step_other(agent, threshold = 0.001) 步骤。这一步把所有预测变量中在数据集中出现频率低于阈值(此处为0.001)的 agent 代理标记为 “Other”。然后,该预处理步骤通过 prep() 函数应用在数据上,结果通过 tidy(number = 2) 展示 out。
<- recipe (avg_price_per_room ~ ., data = hotel_train) %>% step_YeoJohnson (lead_time) %>% step_other (agent, threshold = 0.001 ) %>% step_dummy (all_nominal_predictors ()) %>% step_zv (all_predictors ()) %>% step_spline_natural (arrival_date_num, deg_free = 10 )<- %>% update_recipe (hotel_other_rec)<- %>% fit_resamples (hotel_rs, control = ctrl, metrics = reg_metrics)
→ A | warning: prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
There were issues with some computations A: x5
There were issues with some computations A: x9
collect_metrics (hotel_other_res)
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 mae standard 16.8 10 0.245 Preprocessor1_Model1
2 rsq standard 0.883 10 0.00530 Preprocessor1_Model1
更新工作流并重新拟合模型 :使用 update_recipe(hotel_other_rec) 更新工作流中的 recipe,然后再次拟合样本,并收集评估指标。
这段代码的目的是处理那些只有少数观察值的类别变量——这里是 agent 变量。这样做可以避免过拟合,并可能提高模型的泛化能力。
使用哈希编码
下面这段代码创建了一个新的预处理 “recipe”,并使用该 “recipe” 更新了工作流,然后再次拟合样本,并收集评估指标。
主要改变是:在新的 “recipe” 中,对 agent 和 company 使用了哈希虚拟编码(hashing trick)。哈希虚拟编码可以有效地处理高基数的分类特征。这是一种维度约减技术,通过将所有类别映射到更小的固定数量的列来实现。
具体步骤包括:
创建新的预处理 “recipe” :新的 “recipe” 包含了以下步骤:
对 lead_time 进行Yeo-Johnson变换。
对 agent 和 company 进行哈希虚拟编码(默认生成32个有符号的指示列)。
对其他名义预测变量进行普通的虚拟编码。
删除所有零方差预测变量。
对 arrival_date_num 进行自然样条变换。
更新工作流 :使用 update_recipe(hash_rec) 来更新工作流中的 “recipe”。
重新拟合模型并收集评估指标 :和之前相同,再次拟合样本,并收集评估指标。
哈希虚拟编码是一种处理高基数分类特征的方法,对于有大量唯一值的分类变量(如 IP 地址,用户 ID 等)非常有用。
<- recipe (avg_price_per_room ~ ., data = hotel_train) %>% step_YeoJohnson (lead_time) %>% # Defaults to 32 signed indicator columns step_dummy_hash (agent) %>% step_dummy_hash (company) %>% # Regular indicators for the others step_dummy (all_nominal_predictors ()) %>% step_zv (all_predictors ()) %>% step_spline_natural (arrival_date_num, deg_free = 10 )<- %>% update_recipe (hash_rec)<- %>% fit_resamples (hotel_rs, control = ctrl, metrics = reg_metrics)
→ A | warning: prediction from rank-deficient fit; consider predict(., rankdeficient="NA")
There were issues with some computations A: x5
There were issues with some computations A: x9
collect_metrics (hotel_hash_res)
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 mae standard 16.7 10 0.254 Preprocessor1_Model1
2 rsq standard 0.884 10 0.00572 Preprocessor1_Model1
Debug recipes
<- prep (hash_rec)
── Recipe ──────────────────────────────────────────────────────────────────────
Number of variables by role
Training data contained 3749 data points and no incomplete rows.
• Yeo-Johnson transformation on: lead_time | Trained
• Feature hashing with: agent | Trained
• Feature hashing with: company | Trained
• Dummy variables from: meal, country, market_segment, ... | Trained
• Zero variance filter removed: dummyhash_agent_09, ... | Trained
• Natural spline expansion: arrival_date_num | Trained
# Get the transformation coefficient tidy (hash_rec_fit, number = 1 )
# A tibble: 1 × 3
terms value id
<chr> <dbl> <chr>
1 lead_time 0.173 YeoJohnson_IpstB
# Get the processed data bake (hash_rec_fit, hotel_train %>% slice (1 : 3 ), contains ("_agent_" ))
# A tibble: 3 × 30
dummyhash_agent_01 dummyhash_agent_02 dummyhash_agent_03 dummyhash_agent_04
<int> <int> <int> <int>
1 0 0 0 0
2 0 -1 0 0
3 0 0 0 0
# ℹ 26 more variables: dummyhash_agent_05 <int>, dummyhash_agent_06 <int>,
# dummyhash_agent_07 <int>, dummyhash_agent_08 <int>,
# dummyhash_agent_10 <int>, dummyhash_agent_11 <int>,
# dummyhash_agent_12 <int>, dummyhash_agent_13 <int>,
# dummyhash_agent_14 <int>, dummyhash_agent_15 <int>,
# dummyhash_agent_16 <int>, dummyhash_agent_18 <int>,
# dummyhash_agent_19 <int>, dummyhash_agent_20 <int>, …