Machine Learning with Tidymodels
什么是机器学习
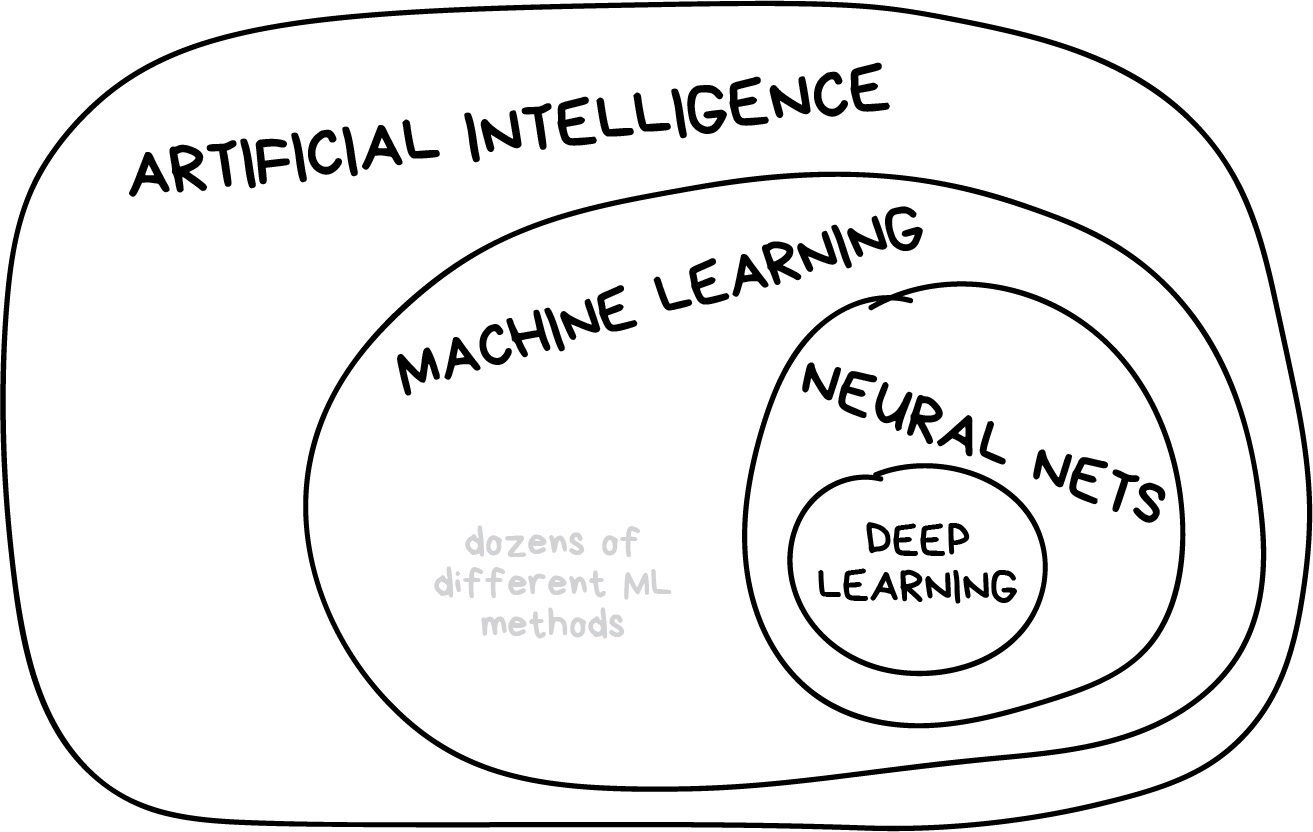
tidymodels 是一个用于机器学习的软件包。那么什么是机器学习呢(Figure 1)?
机器学习(Machine Learning,简称ML)是一种人工智能(Artificial Intelligence,简称AI)的分支领域,致力于研究如何让计算机系统通过经验学习改善性能。机器学习的目标是让计算机能够从数据中学习,自动识别模式、进行预测,并不断地提高自身的性能。
在传统的编程中,程序员编写规则和算法来指导计算机执行特定的任务。而在机器学习中,我们提供大量的数据和相应的结果(标签),让计算机自己学习从数据中提取模式和规律,而不是显式地编写详尽的规则。
机器学习任务通常可以分为以下几类:
监督学习(Supervised Learning):在监督学习中,算法接收带有标签的训练数据,学习输入与输出之间的映射关系。目标是使算法能够对新的、未标记的数据进行准确的预测或分类。
- 分类(Classification):预测输入属于哪个类别,例如垃圾邮件检测、手写数字识别等。
- 回归(Regression):预测一个连续值,例如房价预测、股票价格预测等。
无监督学习(Unsupervised Learning):在无监督学习中,算法接收未标记的训练数据,目标是发现数据中的模式、结构或关系。
- 聚类(Clustering):将数据划分为不同的组,使组内的数据相似度较高,组间相似度较低。
- 降维(Dimensionality Reduction):减少数据的维度,保留重要的特征,例如主成分分析(PCA)。
强化学习(Reinforcement Learning):在强化学习中,算法通过与环境的交互学习,通过尝试最大化累积奖励来决定最佳的行为策略。这种学习方式通常涉及到代理(Agent)和环境之间的交互。
- 代表性应用:游戏玩家、自动驾驶汽车。
机器学习使用多种技术和算法,包括决策树、支持向量机、神经网络、朴素贝叶斯、K近邻等。这些方法在不同的问题和数据情境中表现良好,选择合适的算法取决于具体的任务和数据特征。机器学习在许多领域取得了显著的成就,如自然语言处理、计算机视觉、医学诊断等。
什么是 tidymodels?
tidymodels 是一个 R 语言的机器学习工具集合,包含了一系列用于统计建模和机器学习的软件包。
它是一个统一的建模框架,为 R 用户提供了一种进行预处理,建模,评估和调整的有序方法。其目标是简化数据分析过程。这个框架集成了很多现有且被广泛使用的R包,使得其具有良好的扩展性。
Tidymodels包含以下几个主要的组件:
Recipes: 这是一种用于数据预处理步骤的样板文件/蓝图。例如,缩放或中心化连续变量,编码分类变量等。rsample: 用于重复抽样,例如交叉验证或bootstrap。parnsip: 用于设置模型规范和引擎。tune: 用于模型调优。workflows: 允许将预处理步骤(即配方)和模型规范合并为单一对象,以便在整个工作流程中保持一致性。yardstick: 用于计算模型的表现和效果。
以下是 tidymodels 主要组成部分及其功能的简要介绍 (Figure 2):

library("tidymodels")── Attaching packages ────────────────────────────────────── tidymodels 1.1.1 ──✔ broom 1.0.5 ✔ recipes 1.0.9
✔ dials 1.2.0 ✔ rsample 1.2.0
✔ dplyr 1.1.4 ✔ tibble 3.2.1
✔ ggplot2 3.4.4 ✔ tidyr 1.3.0
✔ infer 1.0.5 ✔ tune 1.1.2
✔ modeldata 1.2.0 ✔ workflows 1.1.3
✔ parsnip 1.1.1 ✔ workflowsets 1.0.1
✔ purrr 1.0.2 ✔ yardstick 1.2.0── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
✖ purrr::discard() masks scales::discard()
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ recipes::step() masks stats::step()
• Search for functions across packages at https://www.tidymodels.org/find/- 模型规范(Model Specification):
parsnip包提供了一个一致的 API,用于定义、估计和调整各种统计模型。它支持多种模型类型,包括回归、分类、聚类等。
library(parsnip) # 创建一个线性回归模型规范 linear_spec <- linear_reg() %>% set_engine("lm") - 预处理(Preprocessing):
rsample和recipes包用于创建和执行数据预处理步骤,例如缺失值处理、变量变换、特征工程等。预处理步骤可以与模型规范无缝集成。
library(recipes) # 创建一个数据预处理配方 preprocess_recipe <- recipe(target ~ ., data = training_data) %>% step_scale(all_predictors()) %>% step_center(all_predictors()) - 模型调参(Model Tuning):
tune包用于执行模型参数调优(tuning)。它提供了一个一致的框架,可以对模型进行网格搜索或其他优化方法,以找到最佳的超参数组合。
library(tune) # 创建一个参数调优网格 grid <- expand.grid(neighbors = c(1, 3, 5)) # 进行参数调优 tune_result <- tune_grid( linear_spec, resamples = training_data, grid = grid ) - 模型评估(Model Evaluation):
yardstick包提供了用于评估模型性能的工具,包括各种指标(如准确率、AUC、RMSE 等)和图形化方法。
library(yardstick) # 评估线性回归模型的性能 linear_metrics <- linear_spec %>% fit(training_data) %>% predict(new_data = testing_data) %>% yardstick::metrics(truth = testing_data$target, estimate = .pred) - 管道(Workflows):
workflows包提供了一种组织模型训练、预处理和评估的框架。它允许你定义整个建模过程,并使整个工作流程可重复和可扩展。
library(workflows)
# 创建一个包含预处理和模型的工作流
wf <- workflow() %>%
add_recipe(preprocess_recipe) %>%
add_model(linear_spec)
# 训练和评估工作流
wf_fit <- wf %>%
fit(training_data) %>%
predict(new_data = testing_data)总体而言,tidymodels 提供了一个一致的框架,使数据科学家和分析师能够更轻松地进行模型开发、评估和调优。它与 tidyverse 的其他部分无缝集成,支持整洁的数据处理和可读性强的代码。
模型的依赖包
下面是为 tidymodels 提供模型的 R 包:
lm(Linear Model):描述: 用于拟合线性回归模型,适用于连续型目标变量。
示例代码:
model <- lm(y ~ x1 + x2, data = my_data)
glm(Generalized Linear Model):描述: 用于广义线性模型,适用于具有不同分布的目标变量,如二项分布(逻辑回归)。
示例代码:
model <- glm(y ~ x1 + x2, family = binomial, data = my_data)
glmnet(Regularized Regression):描述: 用于 L1 和 L2 正则化的线性和广义线性模型,适用于处理高维数据集。
示例代码:
library(glmnet) model <- cv.glmnet(x, y, family = "gaussian")
keras(Regression using TensorFlow):描述: 提供了使用深度学习框架 TensorFlow 进行回归的功能。
示例代码:
library(keras) model <- keras_model_sequential() %>% layer_dense(units = 1, input_shape = c(n_features))
stan(Bayesian Regression):描述: 使用概率编程语言 Stan 进行贝叶斯线性回归。
示例代码:
library(rstan) model <- stan_model("linear_regression.stan")
spark(Large Data Sets):描述: 提供了使用 Apache Spark 处理大规模数据集的功能,包括分布式回归。
示例代码:
library(sparklyr) sc <- spark_connect(master = "local") model <- spark_lm(sc, mpg ~ wt + hp, data = mtcars)
这些包涵盖了不同类型回归任务的需求,从传统的线性回归到深度学习和贝叶斯回归。